1 本节介绍
📝本节您将学习如何通过庐山派来人体关键点,如无特殊说明,以后所有例程的显示设备均为通过外接立创·3.1寸屏幕扩展板,在3.1寸小屏幕上显示。若用户无3.1寸屏幕扩展板也可以正常在IDE的缓冲区,只是受限于USB带宽,可能会帧率较低或卡顿。
🏆学习目标
1️⃣如何用庐山派开发板去进行人体关键点检测。
庐山派开发板的固件是存储在TF中的,模型文件已经提前写入到固件中了,所以大家只需要复制下面的代码到IDE,传递到开发板上就可以正常运行了。无需再额外拷贝,至于后面需要拷贝自己训练的模型那就是后话了。
本节的主要内容是用庐山派开发板来识别人类身体的特定部位(也就是关键点)的坐标位置,比如头部、肩膀、肘部、手腕、膝盖等人体关节或身体主要部位的位置信息。利用关键点检测,我们可以提取关于人体动作的结构化数据,然后把它应用到体感游戏、运动监测、行为分析等多种场景。
2 代码例程
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import utime
import image
import random
import gc
import sys
import aidemo
# 自定义人体关键点检测类
class PersonKeyPointApp(AIBase):
def __init__(self,kmodel_path,model_input_size,confidence_threshold=0.2,nms_threshold=0.5,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
self.kmodel_path=kmodel_path
# 模型输入分辨率
self.model_input_size=model_input_size
# 置信度阈值设置
self.confidence_threshold=confidence_threshold
# nms阈值设置
self.nms_threshold=nms_threshold
# sensor给到AI的图像分辨率
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 显示分辨率
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
self.debug_mode=debug_mode
#骨骼信息
self.SKELETON = [(16, 14),(14, 12),(17, 15),(15, 13),(12, 13),(6, 12),(7, 13),(6, 7),(6, 8),(7, 9),(8, 10),(9, 11),(2, 3),(1, 2),(1, 3),(2, 4),(3, 5),(4, 6),(5, 7)]
#肢体颜色
self.LIMB_COLORS = [(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 255, 51, 255),(255, 255, 51, 255),(255, 255, 51, 255),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0)]
#关键点颜色,共17个
self.KPS_COLORS = [(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 0, 255, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 255, 128, 0),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255),(255, 51, 153, 255)]
# Ai2d实例,用于实现模型预处理
self.ai2d=Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
# 配置预处理操作,这里使用了pad和resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,您可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
top,bottom,left,right=self.get_padding_param()
self.ai2d.pad([0,0,0,0,top,bottom,left,right], 0, [0,0,0])
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义当前任务的后处理
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
# 这里使用了aidemo库的person_kp_postprocess接口
results = aidemo.person_kp_postprocess(results[0],[self.rgb888p_size[1],self.rgb888p_size[0]],self.model_input_size,self.confidence_threshold,self.nms_threshold)
return results
#绘制结果,绘制人体关键点
def draw_result(self,pl,res):
with ScopedTiming("display_draw",self.debug_mode >0):
if res[0]:
pl.osd_img.clear()
kpses = res[1]
for i in range(len(res[0])):
for k in range(17+2):
if (k < 17):
kps_x,kps_y,kps_s = round(kpses[i][k][0]),round(kpses[i][k][1]),kpses[i][k][2]
kps_x1 = int(float(kps_x) * self.display_size[0] // self.rgb888p_size[0])
kps_y1 = int(float(kps_y) * self.display_size[1] // self.rgb888p_size[1])
if (kps_s > 0):
pl.osd_img.draw_circle(kps_x1,kps_y1,5,self.KPS_COLORS[k],4)
ske = self.SKELETON[k]
pos1_x,pos1_y= round(kpses[i][ske[0]-1][0]),round(kpses[i][ske[0]-1][1])
pos1_x_ = int(float(pos1_x) * self.display_size[0] // self.rgb888p_size[0])
pos1_y_ = int(float(pos1_y) * self.display_size[1] // self.rgb888p_size[1])
pos2_x,pos2_y = round(kpses[i][(ske[1] -1)][0]),round(kpses[i][(ske[1] -1)][1])
pos2_x_ = int(float(pos2_x) * self.display_size[0] // self.rgb888p_size[0])
pos2_y_ = int(float(pos2_y) * self.display_size[1] // self.rgb888p_size[1])
pos1_s,pos2_s = kpses[i][(ske[0] -1)][2],kpses[i][(ske[1] -1)][2]
if (pos1_s > 0.0 and pos2_s >0.0):
pl.osd_img.draw_line(pos1_x_,pos1_y_,pos2_x_,pos2_y_,self.LIMB_COLORS[k],4)
gc.collect()
else:
pl.osd_img.clear()
# 计算padding参数
def get_padding_param(self):
dst_w = self.model_input_size[0]
dst_h = self.model_input_size[1]
input_width = self.rgb888p_size[0]
input_high = self.rgb888p_size[1]
ratio_w = dst_w / input_width
ratio_h = dst_h / input_high
if ratio_w < ratio_h:
ratio = ratio_w
else:
ratio = ratio_h
new_w = (int)(ratio * input_width)
new_h = (int)(ratio * input_high)
dw = (dst_w - new_w) / 2
dh = (dst_h - new_h) / 2
top = int(round(dh - 0.1))
bottom = int(round(dh + 0.1))
left = int(round(dw - 0.1))
right = int(round(dw - 0.1))
return top, bottom, left, right
if __name__=="__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="lcd"
# k230保持不变,k230d可调整为[640,360]
rgb888p_size = [1920, 1080]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 模型路径
kmodel_path="/sdcard/examples/kmodel/yolov8n-pose.kmodel"
# 其它参数设置
confidence_threshold = 0.2
nms_threshold = 0.5
# 初始化PipeLine
pl=PipeLine(rgb888p_size=rgb888p_size,display_size=display_size,display_mode=display_mode)
pl.create()
# 初始化自定义人体关键点检测实例
person_kp=PersonKeyPointApp(kmodel_path,model_input_size=[320,320],confidence_threshold=confidence_threshold,nms_threshold=nms_threshold,rgb888p_size=rgb888p_size,display_size=display_size,debug_mode=0)
person_kp.config_preprocess()
try:
while True:
os.exitpoint()
with ScopedTiming("total",1):
# 获取当前帧数据
img=pl.get_frame()
# 推理当前帧
res=person_kp.run(img)
# 绘制结果到PipeLine的osd图像
person_kp.draw_result(pl,res)
# 显示当前的绘制结果
pl.show_image()
gc.collect()
except Exception as e:
sys.print_exception(e)
finally:
person_kp.deinit()
pl.destroy()以上代码的主要流程如下,还是和之前的AI相关代码一样:
- 采集图像:从摄像头(默认摄像头是CSI2接口上的)获得原始图像。
- 预处理:对图像进行
resize、pad、normalize等操作,让输入满足模型的格式要求。 - 模型推理:将图像输入到训练好的人体关键点检测模型(我们这个例子里面是“yolov8n-pose”,已经存储在TF卡里面了)得到模型输出。
- 后处理:根据模型输出获取关键点坐标、得分等信息。
- 可视化:将检测到的关键点和人体骨架连线画到屏幕或图像上,方便调试或演示。
在PersonKeyPointApp类的开头,定义了骨骼连线SKELETON与颜色LIMB_COLORS:用于指定“哪些关键点之间需要连线”以及每根连线的颜色。KPS_COLORS是每个关键点的颜色。这样一来,每个关节点的显示都有独立颜色,便于区分。
然后就到【预处理】了config_preprocess(),先用pad()来填充,包装图片的长款比和模型的输入是一致的,再用resize()吧原图缩放到模型的输入尺寸里。
【后处理】postprocess()也是调用了aidemo.person_kp_postprocess来完成置信度阈值及 NMS (检测框去重)的配置,在这里得到的result就会返回是否检测到目标人体及每个人体的所有关键点坐标和置信度分数。
【可视化】draw_result()中进行了进行了结果的展现:res[0]表示是否存在检测到的人体,若不存在,就直接清空图像。kpses = res[1]里面存放了当前帧所有检测到的人体关键点坐标与置信度,每个人对应一个17关键点的列表。接下来就是根据SKELETON中指定的关键对进行连线处理了。需要注意的是这里因为推理输入尺寸和显示尺寸不同,因此做了一个按比例的映射,保证画在显示设备上的不同分辨率显示时位置是正确的。
3 实际运行
还是先准备一个图片: 
在IDE中运行效果如下图所示: 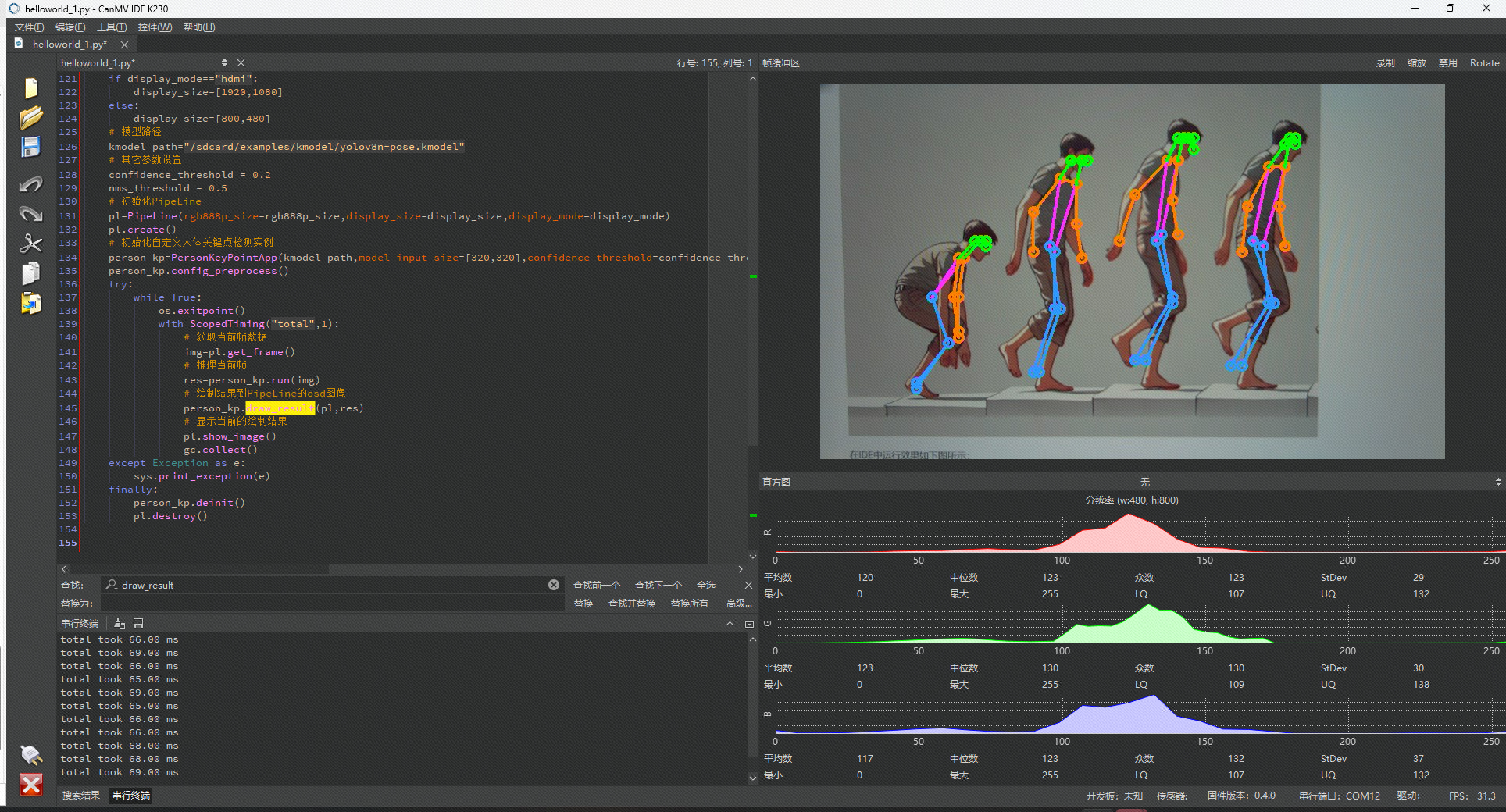
4 如何提取人体关键点数据?
可以在主循环中添加如下代码:
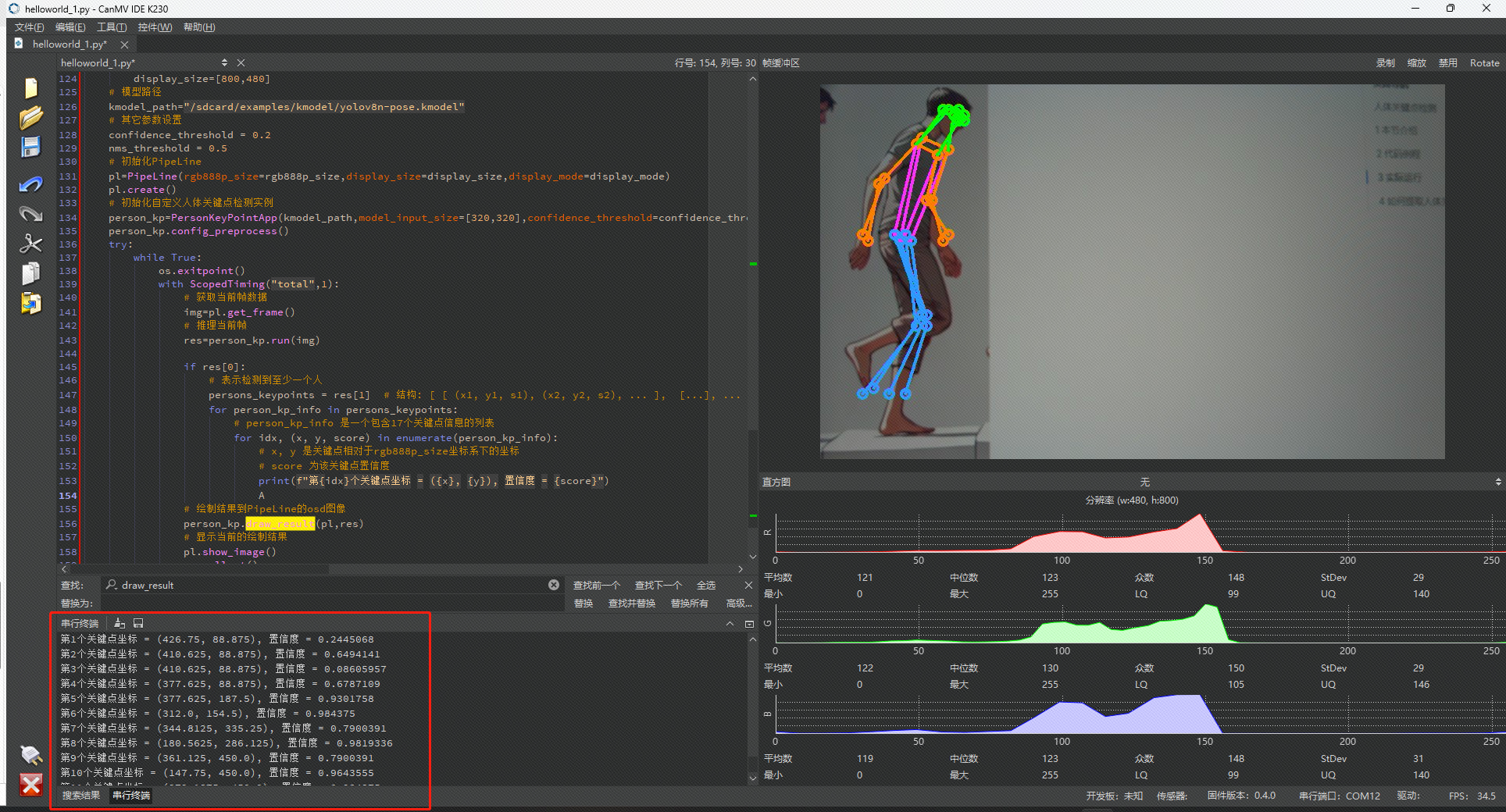
res = person_kp.run(img) #在这句函数下面加
if res[0]:
# 表示检测到至少一个人
persons_keypoints = res[1] # 结构: [ [ (x1, y1, s1), (x2, y2, s2), ... ], [...], ... ]
for person_kp_info in persons_keypoints:
# person_kp_info 是一个包含17个关键点信息的列表
for idx, (x, y, score) in enumerate(person_kp_info):
# x, y 是关键点相对于rgb888p_size坐标系下的坐标
# score 为该关键点置信度
print(f"第{idx}个关键点坐标 = ({x}, {y}), 置信度 = {score}")在IDE中运行效果如下图所示: