1 AI Demo开发框架
为了帮助用户简化 AI 部分的开发,基于 K230_CanMV 提供的 API 接口,我们搭建了配套的 AI 开发框架。框架结构如下图所示:
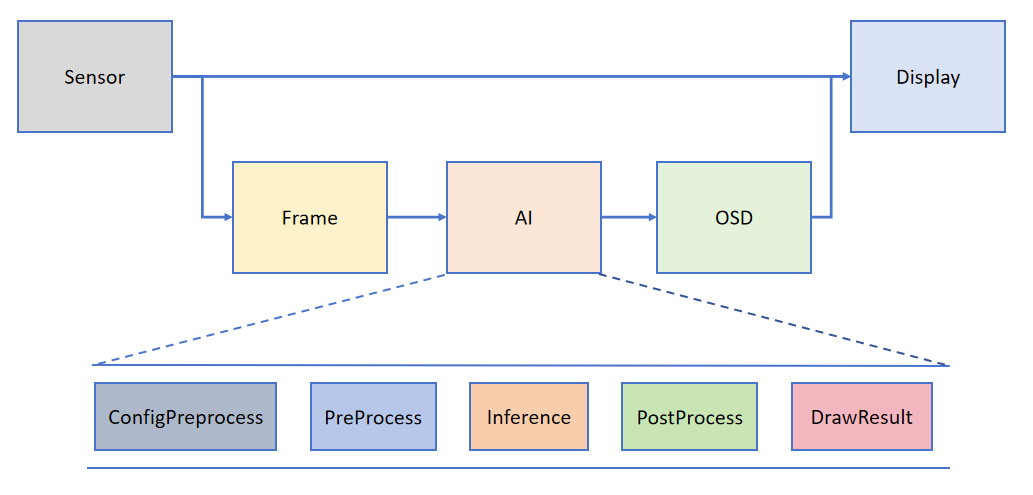
Camera 默认输出两路图像:一路格式为 YUV420SP (Sensor.YUV420SP),直接提供给 Display 显示;另一路格式为 RGBP888 (Sensor.RGBP888),则用于 AI 部分进行处理。AI 主要负责任务的前处理、推理和后处理流程。处理完成后,结果将绘制在 OSD 图像实例上,并发送给 Display 进行叠加显示。
TIP
PipeLine 流程封装主要简化视觉任务的开发过程。您可以使用 'get_frame' 获取一帧图像以进行机器视觉处理;如果您希望自定义 AI 过程,请参考 face_detection。若使用音频相关的 AI,请参考 demo 中的 keyword_spotting 和 tts_zh 两个示例。
2 接口封装
为了方便用户开发,基于上述框架,对从 Camera 获取图像、AI2D 预处理、kmodel模型推理部分的通用功能做了封装。封装接口请参考:AI Demo API
3 应用方法和示例
3.1 概述
用户可根据具体的AI场景自写任务类继承AIBase,可以将任务分为如下四类:单模型任务、多模型任务,自定义预处理任务、无预处理任务。不同任务需要编写不同的代码实现,具体如下图所示:
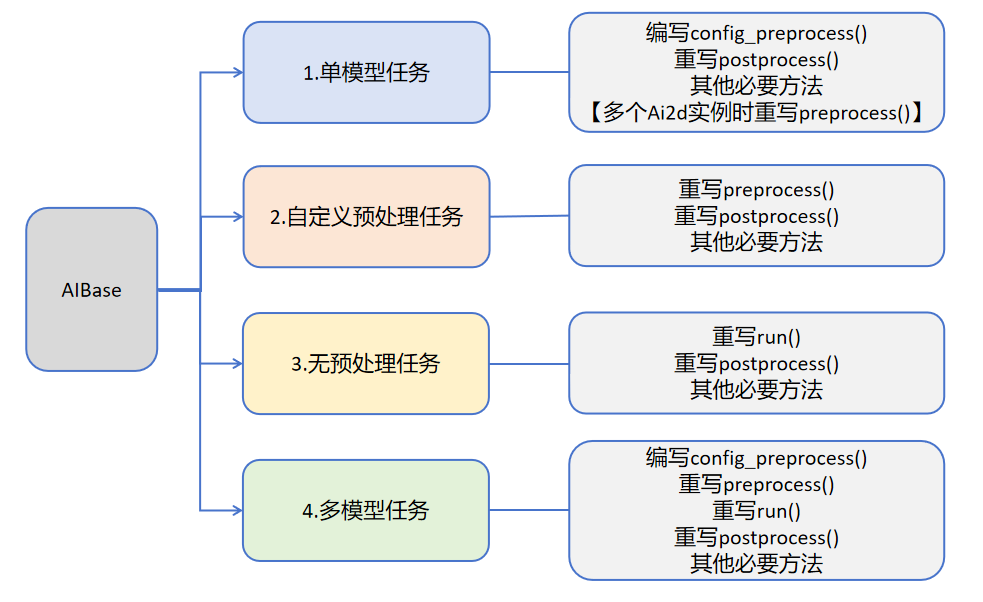
关于不同任务的介绍:
| 任务类型 | 任务描述 | 代码说明 |
|---|---|---|
| 单模型任务 | 该任务只有一个模型,只需要关注该模型的前处理、推理、后处理过程,此类任务的前处理使用Ai2d实现,可能使用一个Ai2d实例,也可能使用多个Ai2d实例,后处理基于场景自定义。 | 编写自定义任务类,主要关注任务类的config_preprocess、postprocess、以及该任务需要的其他方法如:draw_result等。 如果该任务包含多个Ai2d实例,则需要重写preprocess,按照预处理的顺序设置预处理阶段的计算过程。 |
| 自定义预处理任务 | 该任务只有一个模型,只需要关注该模型的前处理、推理、后处理过程,此类任务的前处理不使用Ai2d实现,可以使用ulab.numpy自定义,后处理基于场景自定义。 | 编写自定义任务类,主要关注任务类的preprocess、postprocess、以及该任务需要的其他方法如:draw_result等 |
| 无预处理任务 | 该任务只有一个模型且不需要预处理,只需要关注该模型的推理和后处理过程,此类任务一般作为多模型任务的一部分,直接对前一个模型的输出做为输入推理,后处理基于需求自定义。 | 编写自定义任务类,主要关注任务类的run(模型推理的整个过程,包括preprocess、inference、postprocess中的全部或某一些步骤)、postprocess、以及该任务需要的其他方法如:draw_results等 |
| 多模型任务 | 该任务包含多个模型,可能是串联,也可能是其他组合方式。对于每个模型基本上属于前三种模型中的一种,最后通过一个完整的任务类将上述模型子任务统一起来。 | 编写多个子模型任务类,不同子模型任务参照前三种任务定义。不同任务关注不同的方法。 编写多模型任务类,将子模型任务类统一起来实现整个场景。 |
3.2. 单模型任务
单模型任务的伪代码结构如下:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
from media.media import *
import nncase_runtime as nn
import ulab.numpy as np
import image
import gc
import sys
# 自定义AI任务类,继承自AIBase基类
class MyAIApp(AIBase):
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
# 调用基类的构造函数
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 模型文件路径
self.kmodel_path = kmodel_path
# 模型输入分辨率
self.model_input_size = model_input_size
# sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
# 显示分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
# 是否开启调试模式
self.debug_mode = debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 配置预处理操作,这里使用了resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/libs/AI2D.py查看
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 配置resize预处理方法
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义当前任务的后处理,results是模型输出array列表,需要根据实际任务重写
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
pass
# 绘制结果到画面上,需要根据任务自己写
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
pass
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 设置模型路径,这里要替换成当前任务模型
kmodel_path = "example_test.kmodel"
rgb888p_size = [1920, 1080]
###### 其它参数########
...
######################
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义AI任务实例
my_ai = MyAIApp(kmodel_path, model_input_size=[320, 320],rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
my_ai.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
res = my_ai.run(img) # 推理当前帧
my_ai.draw_result(pl, res) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
my_ai.deinit() # 反初始化
pl.destroy() # 销毁PipeLine实例下面以人脸检测为例给出示例代码:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import utime
import image
import random
import gc
import sys
import aidemo
# 自定义人脸检测类,继承自AIBase基类
class FaceDetectionApp(AIBase):
def __init__(self, kmodel_path, model_input_size, anchors, confidence_threshold=0.5, nms_threshold=0.2, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode) # 调用基类的构造函数
self.kmodel_path = kmodel_path # 模型文件路径
self.model_input_size = model_input_size # 模型输入分辨率
self.confidence_threshold = confidence_threshold # 置信度阈值
self.nms_threshold = nms_threshold # NMS(非极大值抑制)阈值
self.anchors = anchors # 锚点数据,用于目标检测
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]] # sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]] # 显示分辨率,并对宽度进行16的对齐
self.debug_mode = debug_mode # 是否开启调试模式
self.ai2d = Ai2d(debug_mode) # 实例化Ai2d,用于实现模型预处理
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8) # 设置Ai2d的输入输出格式和类型
# 配置预处理操作,这里使用了pad和resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0): # 计时器,如果debug_mode大于0则开启
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size # 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
top, bottom, left, right = self.get_padding_param() # 获取padding参数
self.ai2d.pad([0, 0, 0, 0, top, bottom, left, right], 0, [104, 117, 123]) # 填充边缘
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel) # 缩放图像
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]]) # 构建预处理流程
# 自定义当前任务的后处理,results是模型输出array列表,这里使用了aidemo库的face_det_post_process接口
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
post_ret = aidemo.face_det_post_process(self.confidence_threshold, self.nms_threshold, self.model_input_size[1], self.anchors, self.rgb888p_size, results)
if len(post_ret) == 0:
return post_ret
else:
return post_ret[0]
# 绘制检测结果到画面上
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
if dets:
pl.osd_img.clear() # 清除OSD图像
for det in dets:
# 将检测框的坐标转换为显示分辨率下的坐标
x, y, w, h = map(lambda x: int(round(x, 0)), det[:4])
x = x * self.display_size[0] // self.rgb888p_size[0]
y = y * self.display_size[1] // self.rgb888p_size[1]
w = w * self.display_size[0] // self.rgb888p_size[0]
h = h * self.display_size[1] // self.rgb888p_size[1]
pl.osd_img.draw_rectangle(x, y, w, h, color=(255, 255, 0, 255), thickness=2) # 绘制矩形框
else:
pl.osd_img.clear()
# 获取padding参数
def get_padding_param(self):
dst_w = self.model_input_size[0] # 模型输入宽度
dst_h = self.model_input_size[1] # 模型输入高度
ratio_w = dst_w / self.rgb888p_size[0] # 宽度缩放比例
ratio_h = dst_h / self.rgb888p_size[1] # 高度缩放比例
ratio = min(ratio_w, ratio_h) # 取较小的缩放比例
new_w = int(ratio * self.rgb888p_size[0]) # 新宽度
new_h = int(ratio * self.rgb888p_size[1]) # 新高度
dw = (dst_w - new_w) / 2 # 宽度差
dh = (dst_h - new_h) / 2 # 高度差
top = int(round(0))
bottom = int(round(dh * 2 + 0.1))
left = int(round(0))
right = int(round(dw * 2 - 0.1))
return top, bottom, left, right
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
# k230保持不变,k230d可调整为[640,360]
rgb888p_size = [1920, 1080]
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 设置模型路径和其他参数
kmodel_path = "/sdcard/examples/kmodel/face_detection_320.kmodel"
# 其它参数
confidence_threshold = 0.5
nms_threshold = 0.2
anchor_len = 4200
det_dim = 4
anchors_path = "/sdcard/examples/utils/prior_data_320.bin"
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len, det_dim))
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义人脸检测实例
face_det = FaceDetectionApp(kmodel_path, model_input_size=[320, 320], anchors=anchors, confidence_threshold=confidence_threshold, nms_threshold=nms_threshold, rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
face_det.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
res = face_det.run(img) # 推理当前帧
face_det.draw_result(pl, res) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
face_det.deinit() # 反初始化
pl.destroy() # 销毁PipeLine实例多个Ai2d实例时的伪代码如下:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
from media.media import *
import nncase_runtime as nn
import ulab.numpy as np
import image
import gc
import sys
# 自定义AI任务类,继承自AIBase基类
class MyAIApp(AIBase):
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
# 调用基类的构造函数
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 模型文件路径
self.kmodel_path = kmodel_path
# 模型输入分辨率
self.model_input_size = model_input_size
# sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
# 显示分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
# 是否开启调试模式
self.debug_mode = debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d_resize = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d_resize.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 实例化Ai2d,用于实现模型预处理
self.ai2d_resize = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d_resize.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 实例化Ai2d,用于实现模型预处理
self.ai2d_crop = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d_crop.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 配置预处理操作,这里使用了resize和crop,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/libs/AI2D.py查看
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 配置resize预处理方法
self.ai2d_resize.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程
self.ai2d_resize.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,640,640])
# 配置crop预处理方法
self.ai2d_crop.crop(0,0,320,320)
# 构建预处理流程
self.ai2d_crop.build([1,3,640,640],[1,3,320,320])
# 假设该任务需要crop和resize预处理,顺序是先resize再crop,该顺序不符合ai2d的处理顺序,因此需要设置两个Ai2d实例分别处理
def preprocess(self,input_np):
resize_tensor=self.ai2d_resize.run(input_np)
resize_np=resize_tensor.to_numpy()
crop_tensor=self.ai2d_crop.run(resize_np)
return [crop_tensor]
# 自定义当前任务的后处理,results是模型输出array列表,需要根据实际任务重写
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
pass
# 绘制结果到画面上,需要根据任务自己写
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
pass
# 重写deinit,释放多个ai2d资源
def deinit(self):
with ScopedTiming("deinit",self.debug_mode > 0):
del self.ai2d_resize
del self.ai2d_crop
super().deinit()
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 设置模型路径,这里要替换成当前任务模型
kmodel_path = "example_test.kmodel"
rgb888p_size = [1920, 1080]
###### 其它参数########
...
######################
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义AI任务实例
my_ai = MyAIApp(kmodel_path, model_input_size=[320, 320],rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
my_ai.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
res = my_ai.run(img) # 推理当前帧
my_ai.draw_result(pl, res) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
my_ai.deinit() # 反初始化
pl.destroy() # 销毁PipeLine实例3.3 自定义预处理任务
对于需要重写前处理(不使用提供的ai2d类,自己手动写预处理)的AI任务伪代码如下:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
from media.media import *
import nncase_runtime as nn
import ulab.numpy as np
import image
import gc
import sys
# 自定义AI任务类,继承自AIBase基类
class MyAIApp(AIBase):
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
# 调用基类的构造函数
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 模型文件路径
self.kmodel_path = kmodel_path
# 模型输入分辨率
self.model_input_size = model_input_size
# sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
# 显示分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
# 是否开启调试模式
self.debug_mode = debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 对于不使用ai2d完成预处理的AI任务,使用封装的接口或者ulab.numpy实现预处理,需要在子类中重写该函数
def preprocess(self,input_np):
#############
#注意自定义预处理过程
#############
return [tensor]
# 自定义当前任务的后处理,results是模型输出array列表,需要根据实际任务重写
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
pass
# 绘制结果到画面上,需要根据任务自己写
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
pass
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 设置模型路径,这里要替换成当前任务模型
kmodel_path = "example_test.kmodel"
rgb888p_size = [1920, 1080]
###### 其它参数########
...
######################
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义AI任务实例
my_ai = MyAIApp(kmodel_path, model_input_size=[320, 320],rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
my_ai.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
res = my_ai.run(img) # 推理当前帧
my_ai.draw_result(pl, res) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
my_ai.deinit() # 反初始化
pl.destroy() # 销毁PipeLine实例以关键词唤醒keyword_spotting为例:
from libs.PipeLine import ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
from media.pyaudio import * # 音频模块
from media.media import * # 软件抽象模块,主要封装媒体数据链路以及媒体缓冲区
import media.wave as wave # wav音频处理模块
import nncase_runtime as nn # nncase运行模块,封装了kpu(kmodel推理)和ai2d(图片预处理加速)操作
import ulab.numpy as np # 类似python numpy操作,但也会有一些接口不同
import aidemo # aidemo模块,封装ai demo相关前处理、后处理等操作
import time # 时间统计
import struct # 字节字符转换模块
import gc # 垃圾回收模块
import os,sys # 操作系统接口模块
# 自定义关键词唤醒类,继承自AIBase基类
class KWSApp(AIBase):
def __init__(self, kmodel_path, threshold, debug_mode=0):
super().__init__(kmodel_path) # 调用基类的构造函数
self.kmodel_path = kmodel_path # 模型文件路径
self.threshold=threshold
self.debug_mode = debug_mode # 是否开启调试模式
self.cache_np = np.zeros((1, 256, 105), dtype=np.float)
# 自定义预处理,返回模型输入tensor列表
def preprocess(self,pcm_data):
pcm_data_list=[]
# 获取音频流数据
for i in range(0, len(pcm_data), 2):
# 每两个字节组织成一个有符号整数,然后将其转换为浮点数,即为一次采样的数据,加入到当前一帧(0.3s)的数据列表中
int_pcm_data = struct.unpack("<h", pcm_data[i:i+2])[0]
float_pcm_data = float(int_pcm_data)
pcm_data_list.append(float_pcm_data)
# 将pcm数据处理为模型输入的特征向量
mp_feats = aidemo.kws_preprocess(fp, pcm_data_list)[0]
mp_feats_np = np.array(mp_feats).reshape((1, 30, 40))
audio_input_tensor = nn.from_numpy(mp_feats_np)
cache_input_tensor = nn.from_numpy(self.cache_np)
return [audio_input_tensor,cache_input_tensor]
# 自定义当前任务的后处理,results是模型输出array列表
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
logits_np = results[0]
self.cache_np= results[1]
max_logits = np.max(logits_np, axis=1)[0]
max_p = np.max(max_logits)
idx = np.argmax(max_logits)
# 如果分数大于阈值,且idx==1(即包含唤醒词),播放回复音频
if max_p > self.threshold and idx == 1:
return 1
else:
return 0
if __name__ == "__main__":
os.exitpoint(os.EXITPOINT_ENABLE)
nn.shrink_memory_pool()
# 设置模型路径和其他参数
kmodel_path = "/sdcard/examples/kmodel/kws.kmodel"
# 其它参数
THRESH = 0.5 # 检测阈值
SAMPLE_RATE = 16000 # 采样率16000Hz,即每秒采样16000次
CHANNELS = 1 # 通道数 1为单声道,2为立体声
FORMAT = paInt16 # 音频输入输出格式 paInt16
CHUNK = int(0.3 * 16000) # 每次读取音频数据的帧数,设置为0.3s的帧数16000*0.3=4800
reply_wav_file = "/sdcard/examples/utils/wozai.wav" # kws唤醒词回复音频路径
# 初始化音频预处理接口
fp = aidemo.kws_fp_create()
# 初始化音频流
p = PyAudio()
p.initialize(CHUNK)
MediaManager.init() #vb buffer初始化
# 用于采集实时音频数据
input_stream = p.open(format=FORMAT,channels=CHANNELS,rate=SAMPLE_RATE,input=True,frames_per_buffer=CHUNK)
# 用于播放回复音频
output_stream = p.open(format=FORMAT,channels=CHANNELS,rate=SAMPLE_RATE,output=True,frames_per_buffer=CHUNK)
# 初始化自定义关键词唤醒实例
kws = KWSApp(kmodel_path,threshold=THRESH,debug_mode=0)
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
pcm_data=input_stream.read()
res=kws.run(pcm_data)
if res:
print("====Detected XiaonanXiaonan!====")
wf = wave.open(reply_wav_file, "rb")
wav_data = wf.read_frames(CHUNK)
while wav_data:
output_stream.write(wav_data)
wav_data = wf.read_frames(CHUNK)
time.sleep(1) # 时间缓冲,用于播放回复声音
wf.close()
else:
print("Deactivated!")
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
input_stream.stop_stream()
output_stream.stop_stream()
input_stream.close()
output_stream.close()
p.terminate()
MediaManager.deinit() #释放vb buffer
aidemo.kws_fp_destroy(fp)
kws.deinit() # 反初始化3.4 无预处理任务
对于不需要预处理(直接输入推理)的AI任务伪代码如下:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
from media.media import *
import nncase_runtime as nn
import ulab.numpy as np
import image
import gc
import sys
# 自定义AI任务类,继承自AIBase基类
class MyAIApp(AIBase):
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
# 调用基类的构造函数
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 模型文件路径
self.kmodel_path = kmodel_path
# 模型输入分辨率
self.model_input_size = model_input_size
# sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
# 显示分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
# 是否开启调试模式
self.debug_mode = debug_mode
# 自定义当前任务的后处理,results是模型输出array列表,需要根据实际任务重写
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
pass
# 对于无预处理的AI任务,需要在子类中重写该函数
def run(self,inputs_np):
# 先将ulab.numpy.ndarray列表转换成tensor列表
tensors=[]
for input_np in inputs_np:
tensors.append(nn.from_numpy(input_np))
# 调用AIBase内的inference函数进行模型推理
results=self.inference(tensors)
# 调用当前子类的postprocess方法进行自定义后处理
outputs=self.postprocess(results)
return outputs
# 绘制结果到画面上,需要根据任务自己写
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
pass
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 设置模型路径,这里要替换成当前任务模型
kmodel_path = "example_test.kmodel"
rgb888p_size = [1920, 1080]
###### 其它参数########
...
######################
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义AI任务实例
my_ai = MyAIApp(kmodel_path, model_input_size=[320, 320],rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
my_ai.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
res = my_ai.run(img) # 推理当前帧
my_ai.draw_result(pl, res) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
my_ai.deinit() # 反初始化
pl.destroy() # 销毁PipeLine实例比如单目标跟踪(nanotracker.py)中的追踪模块,只需要对模版模型和实时推理模型的输出作为追踪模型的输入,不需要预处理:
class TrackerApp(AIBase):
def __init__(self,kmodel_path,crop_input_size,thresh,rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,rgb888p_size,debug_mode)
# kmodel路径
self.kmodel_path=kmodel_path
# crop模型的输入尺寸
self.crop_input_size=crop_input_size
# 跟踪框阈值
self.thresh=thresh
# 跟踪框宽、高调整系数
self.CONTEXT_AMOUNT = 0.5
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# debug模式
self.debug_mode=debug_mode
# 可以不定义
self.ai2d=Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
# 可以不定义
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
pass
# 重写run函数,因为没有预处理过程,所以原来run操作中包含的preprocess->inference->postprocess不合适,这里只包含inference->postprocess
def run(self,input_np_1,input_np_2,center_xy_wh):
input_tensors=[]
input_tensors.append(nn.from_numpy(input_np_1))
input_tensors.append(nn.from_numpy(input_np_2))
results=self.inference(input_tensors)
return self.postprocess(results,center_xy_wh)
# 自定义后处理,results是模型输出array的列表,这里使用了aidemo的nanotracker_postprocess列表
def postprocess(self,results,center_xy_wh):
with ScopedTiming("postprocess",self.debug_mode > 0):
det = aidemo.nanotracker_postprocess(results[0],results[1],[self.rgb888p_size[1],self.rgb888p_size[0]],self.thresh,center_xy_wh,self.crop_input_size[0],self.CONTEXT_AMOUNT)
return det3.5 多模型任务
这里以双模型串联推理为例,给出的伪代码如下:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
from media.media import *
import nncase_runtime as nn
import ulab.numpy as np
import image
import gc
import sys
# 自定义AI任务类,继承自AIBase基类
class MyAIApp_1(AIBase):
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
# 调用基类的构造函数
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 模型文件路径
self.kmodel_path = kmodel_path
# 模型输入分辨率
self.model_input_size = model_input_size
# sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
# 显示分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
# 是否开启调试模式
self.debug_mode = debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 配置预处理操作,这里使用了resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/libs/AI2D.py查看
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 配置resize预处理方法
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义当前任务的后处理,results是模型输出array列表,需要根据实际任务重写
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
pass
# 自定义AI任务类,继承自AIBase基类
class MyAIApp_2(AIBase):
def __init__(self, kmodel_path, model_input_size, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
# 调用基类的构造函数
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# 模型文件路径
self.kmodel_path = kmodel_path
# 模型输入分辨率
self.model_input_size = model_input_size
# sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]]
# 显示分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]]
# 是否开启调试模式
self.debug_mode = debug_mode
# 实例化Ai2d,用于实现模型预处理
self.ai2d = Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8)
# 配置预处理操作,这里使用了resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/libs/AI2D.py查看
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size
# 配置resize预处理方法
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# 构建预处理流程
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义当前任务的后处理,results是模型输出array列表,需要根据实际任务重写
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
pass
class MyApp:
def __init__(kmodel1_path,kmodel2_path,kmodel1_input_size,kmodel2_input_size,rgb888p_size,display_size,debug_mode):
# 创建两个模型推理的实例
self.app_1=MyApp_1(kmodel1_path,kmodel1_input_size,rgb888p_size,display_size,debug_mode)
self.app_2=MyApp_2(kmodel2_path,kmodel2_input_size,rgb888p_size,display_size,debug_mode)
self.app_1.config_preprocess()
# 编写run函数,具体代码根据AI任务的需求编写,此处只是给出一个示例
def run(self,input_np):
outputs_1=self.app_1.run(input_np)
outputs_2=[]
for out in outputs_1:
self.app_2.config_preprocess(out)
out_2=self.app_2.run(input_np)
outputs_2.append(out_2)
return outputs_1,outputs_2
# 绘制
def draw_result(self,pl,outputs_1,outputs_2):
pass
######其他函数########
# 省略
####################
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
rgb888p_size = [1920, 1080]
# 设置模型路径,这里要替换成当前任务模型
kmodel1_path = "test_kmodel1.kmodel"
kmdoel1_input_size=[320,320]
kmodel2_path = "test_kmodel2.kmodel"
kmodel2_input_size=[48,48]
###### 其它参数########
# 省略
######################
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义AI任务实例
my_ai = MyApp(kmodel1_path,kmodel2_path, kmodel1_input_size,kmodel2_input_size,rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
my_ai.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
outputs_1,outputs_2 = my_ai.run(img) # 推理当前帧
my_ai.draw_result(pl, outputs_1,outputs_2) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
my_ai.app_1.deinit() # 反初始化
my_ai.app_2.deinit()
pl.destroy() # 销毁PipeLine实例示例代码请参考车牌检测识别:烧录固件,打开IDE,选择文件->打开文件,按照如下路径选择对应的脚本打开:此电脑->CanMV->sdcard->examples->05-AI-Demo->licence_det_rec.py。
4 参考文档
4.1 K230 canmv文档
文档链接:Welcome to K230 CanMV’s documentation! — K230 CanMV 文档 (canaan-creative.com)
4.2 Ulab库支持
链接: ulab – Manipulate numeric data similar to numpy — Adafruit CircuitPython 9.1.0-beta.3 documentation
提示
本文直接转自嘉楠开发者社区的文档:3. AI Demo说明文档 — CanMV K230,更深入及更详细请查看嘉楠官方文档:嘉楠开发者社区-文档中心