10、SPI数据的传输

- spi_transfer
- spi_message
一、数据结构
spi 数据传输主要使用了 spi_message 和 spi_transfer 结构, 多个 spi_transfer 够成一个 spi_message.
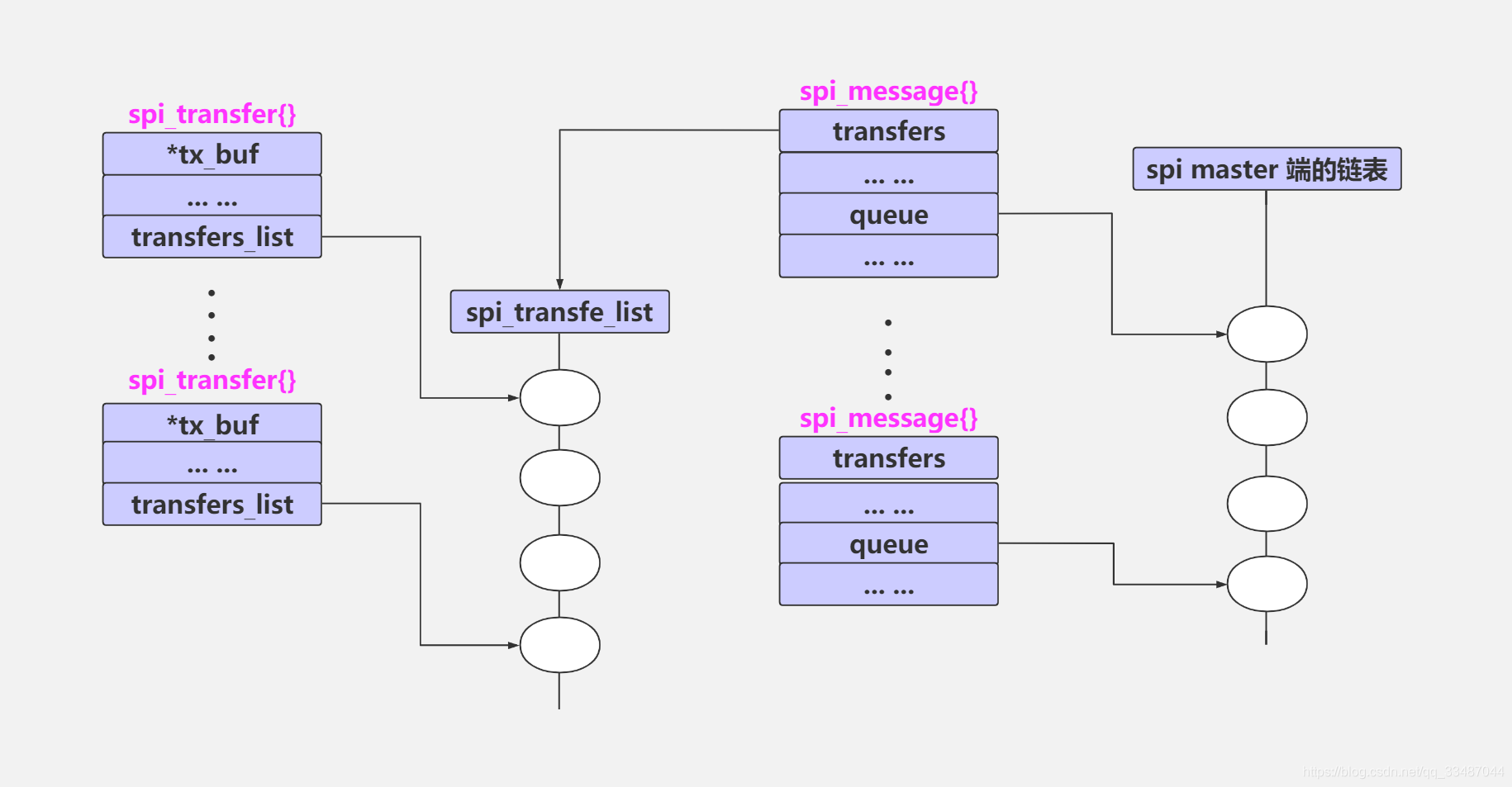
在进行 spi 数据传输的时候,如果有同一时段有多个 spi msg 要处理,则会将要处理的 msg 连成一个链表,等待依次处理,该链表头一般都是包含了 spi_master{}的实际控制端。
1、spi_transfer 结构体
文件目录:kernel\include\linux\spi\spi.h
struct spi_transfer {
/* it's ok if tx_buf == rx_buf (right?)
* for MicroWire, one buffer must be null
* buffers must work with dma_*map_single() calls, unless
* spi_message.is_dma_mapped reports a pre-existing mapping
*/
const void *tx_buf;
void *rx_buf;
unsigned len;
dma_addr_t tx_dma;
dma_addr_t rx_dma;
struct sg_table tx_sg;
struct sg_table rx_sg;
unsigned cs_change:1;
unsigned tx_nbits:3;
unsigned rx_nbits:3;
#define SPI_NBITS_SINGLE 0x01 /* 1bit transfer */
#define SPI_NBITS_DUAL 0x02 /* 2bits transfer */
#define SPI_NBITS_QUAD 0x04 /* 4bits transfer */
u8 bits_per_word;
u16 delay_usecs;
u32 speed_hz;
struct list_head transfer_list;
};以下是 spi_transfer 结构中关键字段的详细解释:
tx_buf(发送缓冲区)
- 存放要发送给设备的数据。
- 如果是“只读”操作(不发数据),这里设为
NULL。 - 如果要用DMA(直接内存访问)传输数据,缓冲区必须支持DMA。
rx_buf(接收缓冲区)
- 用来保存从设备读取的数据。
- 属性与
tx_buf相同(比如是否支持DMA)。 - 如果是“只写”操作(不读数据),这里设为
NULL。
tx_dma 和 rx_dma(DMA 地址)
- 当系统使用DMA时,这两个字段分别存放
tx_buf和rx_buf的物理地址。 - 仅在
spi_message标记为支持DMA时生效(spi_message.is_dma_mapped = 1)。
- 当系统使用DMA时,这两个字段分别存放
len(数据长度)
- 表示发送和接收缓冲区的大小(单位:字节)。
- 如果同时使用
tx_buf和rx_buf,两者的长度必须相同。
speed_hz(传输速度)
- 覆盖设备默认的SPI时钟速度(默认值在
spi_device.max_speed_hz中设置)。 - 如果设为
0,则使用设备的默认速度。
- 覆盖设备默认的SPI时钟速度(默认值在
bits_per_word(每字位数)
- 指定一次传输中每个“字”的位数(例如8位、16位)。
- 覆盖设备默认的位数设置(默认值在
spi_device.bits_per_word中)。 - 如果设为
0,则使用设备的默认值。
cs_change(片选状态)
- 决定本次传输结束后是否切换片选信号(Chip Select)的状态。
- 如果设为
1,传输后会切换片选状态(例如从“选中”变为“未选中”)。
delay_usecs(延迟时间)
- 传输完成后,等待指定的微秒数(单位:微秒)。
- 这个延迟发生在片选信号状态切换(如果有的话)和下一次传输开始之间。
2、spi_message
文件目录:kernel\include\linux\spi\spi.h
SPI消息结构(struct spi_message)的作用是将一个或多个SPI数据传输请求打包成一个整体任务。当这个任务开始执行时,系统会锁定所使用的SPI通信总线,直到所有打包在消息中的数据传输全部完成才会释放总线资源。这个结构的具体定义可以在Linux内核的include/linux/spi/spi.h头文件中找到。·
struct spi_message {
struct list_head transfers;
struct spi_device *spi;
unsigned is_dma_mapped:1;
/* REVISIT: we might want a flag affecting the behavior of the
* last transfer ... allowing things like "read 16 bit length L"
* immediately followed by "read L bytes". Basically imposing
* a specific message scheduling algorithm.
*
* Some controller drivers (message-at-a-time queue processing)
* could provide that as their default scheduling algorithm. But
* others (with multi-message pipelines) could need a flag to
* tell them about such special cases.
*/
/* completion is reported through a callback */
void (*complete)(void *context);
void *context;
unsigned frame_length;
unsigned actual_length;
int status;
/* for optional use by whatever driver currently owns the
* spi_message ... between calls to spi_async and then later
* complete(), that's the spi_master controller driver.
*/
struct list_head queue;
void *state;
};- 传输列表(transfers) 存储消息中所有传输任务的列表。后面会说明如何将具体传输任务添加到这里。
- 是否使用DMA(is_dma_mapped) 标记是否通过DMA(直接内存访问技术)执行传输。如果开启DMA,程序需要同时为每个数据块提供DMA专用地址和普通内存地址。
- 完成回调(complete) 任务完成后自动执行的函数。context参数会作为额外信息传入这个函数。
- 总字节数(frame_length) 自动统计消息中所有数据的总字节数,不需要手动计算。
- 实际传输量(actual_length) 记录所有成功传输的数据总字节数。
- 状态码(status) 返回任务执行结果:成功时显示0,失败时显示带负号的错误代码(比如内存不足时显示-ENOMEM)。
二、数据发送程序分析
spi_sync函数用于执行同步数据传输。它的运作原理是调用__spi_queued_transfer函数完成数据交换,只是在调用时将第三个参数设置为false。该函数的代码定义在Linux内核的drivers/spi/spi.c文件中。
/**
* spi_sync - blocking/synchronous SPI data transfers
* @spi: device with which data will be exchanged
* @message: describes the data transfers
* Context: can sleep
*
* This call may only be used from a context that may sleep. The sleep
* is non-interruptible, and has no timeout. Low-overhead controller
* drivers may DMA directly into and out of the message buffers.
*
* Note that the SPI device's chip select is active during the message,
* and then is normally disabled between messages. Drivers for some
* frequently-used devices may want to minimize costs of selecting a chip,
* by leaving it selected in anticipation that the next message will go
* to the same chip. (That may increase power usage.)
*
* Also, the caller is guaranteeing that the memory associated with the
* message will not be freed before this call returns.
*
* Return: zero on success, else a negative error code.
*/
int spi_sync(struct spi_device *spi, struct spi_message *message)
{
int ret;
mutex_lock(&spi->controller->bus_lock_mutex);
ret = __spi_sync(spi, message);
mutex_unlock(&spi->controller->bus_lock_mutex);
return ret;
}spi_sync会调用同步接口 __spi_sync
static int __spi_sync(struct spi_device *spi, struct spi_message *message)
{
DECLARE_COMPLETION_ONSTACK(done); // 声明dowe变量
int status;
struct spi_controller *ctlr = spi->controller;
unsigned long flags;
status = __spi_validate(spi, message);
if (status != 0)
return status;
message->complete = spi_complete; // 传输完成回调函数
message->context = &done; // 提供给complete的可选参数
message->spi = spi; // 设置目标SPI从设备
SPI_STATISTICS_INCREMENT_FIELD(&ctlr->statistics, spi_sync);
SPI_STATISTICS_INCREMENT_FIELD(&spi->statistics, spi_sync);
/* If we're not using the legacy transfer method then we will
* try to transfer in the calling context so special case.
* This code would be less tricky if we could remove the
* support for driver implemented message queues.
*/
if (ctlr->transfer == spi_queued_transfer) { // 之前已经初始化,这一步会进入
spin_lock_irqsave(&ctlr->bus_lock_spinlock, flags);
trace_spi_message_submit(message);
status = __spi_queued_transfer(spi, message, false); // 第三个参数设置为了false
spin_unlock_irqrestore(&ctlr->bus_lock_spinlock, flags);
} else {
status = spi_async_locked(spi, message);
}
if (status == 0) { //SPI控制器没有数据在传输,因此可以进行数据传输
/* Push out the messages in the calling context if we
* can.
*/
if (ctlr->transfer == spi_queued_transfer) {
SPI_STATISTICS_INCREMENT_FIELD(&ctlr->statistics,
spi_sync_immediate);
SPI_STATISTICS_INCREMENT_FIELD(&spi->statistics,
spi_sync_immediate);
__spi_pump_messages(ctlr, false); // 进行SPI数据传输
}
wait_for_completion(&done); // 等待传输完成
status = message->status;
}
message->context = NULL;
return status;
}在调用 __spi_queued_transfer 函数时:
- 如果 SPI 正在忙于传输数据,会直接返回错误
-ESHUTDOWN; - 如果 SPI 空闲,就把需要传输的数据包(
spi_message)加入控制器的队列(spi_controller->queue),然后返回成功0。
::: 同步传输和异步传输的区别:
异步传输方式:
将一个“后台任务”(__spi_pump_messages)提交给系统线程池,由系统在空闲时自动处理数据传输;
这个任务会慢慢完成数据发送,调用方不需要等待结果。
同步传输方式:
立即直接调用 __spi_pump_messages 函数,强制在当前流程中处理数据传输;
根据具体情况,有两种可能的行为:
情况1:如果硬件空闲,直接调用控制器的 transfer_one_message 立即发送数据;
情况2:如果硬件被占用了,就把任务提交到系统线程池(和异步方式一样);
无论哪种情况,调用方会一直等待传输完成后再继续执行。 :::
关于 **__spi_pump_messages** 函数:
这个函数负责处理队列中的所有待发送数据包;
它会被两种场景调用:
- 由系统后台线程自动调用(异步模式);
- 被
spi_sync函数直接调用(同步模式);
调用时的区别:
- 异步模式传入参数
true; - 同步模式传入参数
false。
- 异步模式传入参数
::: 总结:
异步:提交任务后立刻返回,后台慢慢处理;
同步:强制立即处理,直到完成才返回结果;
核心差异在于是否需要等待传输完成,以及任务调度的方式不同。 :::
/**
* __spi_pump_messages - function which processes spi message queue
* @ctlr: controller to process queue for
* @in_kthread: true if we are in the context of the message pump thread
*
* This function checks if there is any spi message in the queue that
* needs processing and if so call out to the driver to initialize hardware
* and transfer each message.
*
* Note that it is called both from the kthread itself and also from
* inside spi_sync(); the queue extraction handling at the top of the
* function should deal with this safely.
*/
static void __spi_pump_messages(struct spi_controller *ctlr, bool in_kthread)
{
unsigned long flags;
bool was_busy = false;
int ret;
/* Lock queue */
spin_lock_irqsave(&ctlr->queue_lock, flags); // 互斥访问 自旋锁 + 关中断
/* Make sure we are not already running a message */
if (ctlr->cur_msg) { // 有msg正在处理,这里直接就返回了,这里直接返回会导致消息丢失么,不会的因为消息已经放入消息队列了,当正在处理的消息被处理完, 会调用spi_finalize_current_message函数,该函数又会重复将__spi_pump_messages作为任务挂到内核工作线程的
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
return;
}
/* If another context is idling the device then defer */
if (ctlr->idling) { // 空闲状态会进入 这个值基本上始终为false
kthread_queue_work(&ctlr->kworker, &ctlr->pump_messages); // 将work加入到worker
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
return;
}
/* Check if the queue is idle */
if (list_empty(&ctlr->queue) || !ctlr->running) { // 在__spi_queue_transfer函数中会将需要传输的消息挂到消息队列;所以这个队列刚开始不为空 这个分支页不会进入; 但是当消息队列消息传输完后,则会进入
if (!ctlr->busy) { // SPI控制器不繁忙,进入 直接返回
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
return;
}
/* Only do teardown in the thread */
if (!in_kthread) { // 异步参数为true 同步参数为false,同步进入
kthread_queue_work(&ctlr->kworker, // 将work加入到worker
&ctlr->pump_messages);
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
return;
}
ctlr->busy = false; // 设置SPI控制器状态不繁忙
ctlr->idling = true; // 设置内核工作线程状态为空闲
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
kfree(ctlr->dummy_rx);
ctlr->dummy_rx = NULL;
kfree(ctlr->dummy_tx);
ctlr->dummy_tx = NULL;
if (ctlr->unprepare_transfer_hardware &&
ctlr->unprepare_transfer_hardware(ctlr))
dev_err(&ctlr->dev,
"failed to unprepare transfer hardware\n");
if (ctlr->auto_runtime_pm) {
pm_runtime_mark_last_busy(ctlr->dev.parent);
pm_runtime_put_autosuspend(ctlr->dev.parent);
}
trace_spi_controller_idle(ctlr);
spin_lock_irqsave(&ctlr->queue_lock, flags);
ctlr->idling = false; // 设置内核工作线程状态为空闲
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
return;
}
/* Extract head of queue */
ctlr->cur_msg = // 从消息队列获取第一个spi_message
list_first_entry(&ctlr->queue, struct spi_message, queue);
list_del_init(&ctlr->cur_msg->queue); // 将第一个spi_message从ctrl->queue队列删除
if (ctlr->busy) // 当前SPI控制器繁忙
was_busy = true;
else
ctlr->busy = true; // 将当前状态设备为繁忙
spin_unlock_irqrestore(&ctlr->queue_lock, flags);
mutex_lock(&ctlr->io_mutex);
if (!was_busy && ctlr->auto_runtime_pm) { // 电源管理相关 忽略
ret = pm_runtime_get_sync(ctlr->dev.parent);
if (ret < 0) {
pm_runtime_put_noidle(ctlr->dev.parent);
dev_err(&ctlr->dev, "Failed to power device: %d\n",
ret);
mutex_unlock(&ctlr->io_mutex);
return;
}
}
if (!was_busy) // 过去不busy则进入
trace_spi_controller_busy(ctlr);
if (!was_busy && ctlr->prepare_transfer_hardware) {
ret = ctlr->prepare_transfer_hardware(ctlr);
if (ret) {
dev_err(&ctlr->dev,
"failed to prepare transfer hardware: %d\n",
ret);
if (ctlr->auto_runtime_pm)
pm_runtime_put(ctlr->dev.parent);
ctlr->cur_msg->status = ret;
spi_finalize_current_message(ctlr);
mutex_unlock(&ctlr->io_mutex);
return;
}
}
trace_spi_message_start(ctlr->cur_msg);
if (ctlr->prepare_message) {
ret = ctlr->prepare_message(ctlr, ctlr->cur_msg);
if (ret) {
dev_err(&ctlr->dev, "failed to prepare message: %d\n",
ret);
ctlr->cur_msg->status = ret;
spi_finalize_current_message(ctlr);
goto out;
}
ctlr->cur_msg_prepared = true;
}
ret = spi_map_msg(ctlr, ctlr->cur_msg);
if (ret) {
ctlr->cur_msg->status = ret;
spi_finalize_current_message(ctlr);
goto out;
}
ret = ctlr->transfer_one_message(ctlr, ctlr->cur_msg); // SPI数据传输
if (ret) {
dev_err(&ctlr->dev,
"failed to transfer one message from queue\n");
goto out;
}
out:
mutex_unlock(&ctlr->io_mutex);
/* Prod the scheduler in case transfer_one() was busy waiting */
if (!ret)
cond_resched();
}- 这段代码的核心逻辑可以这样理解:
主要流程分三步走:
如果正在传输消息(cur_msg不为空):
- 直接返回,暂不处理新消息。
- 不会丢失消息:因为新消息已经被放入队列,当前消息处理完成后,系统会自动触发下一轮处理,继续从队列取消息。
如果当前空闲(无消息在传,且工作线程没任务):
- 将任务
__spi_pump_messages挂到内核工作线程,让它开始工作。 - (类似“唤醒闲置的员工,让他去处理任务队列”)
- 将任务
如果工作线程正在忙(但队列里还有消息):
从队列取出第一个消息,标记为“当前处理中”。
准备传输:
- 如果之前刚处理完一个消息,先调用驱动的
prepare_transfer_hardware做硬件准备。 - 调用驱动的
prepare_message函数做传输前的准备工作(比如配置DMA)。 - 如果准备失败,直接标记错误,否则继续。
- 如果之前刚处理完一个消息,先调用驱动的
实际传输:
- 调用驱动的
transfer_one_message函数(或默认的通用实现),真正开始发送数据。
- 调用驱动的
循环机制的核心:
传输完成后,会调用
- 清空当前处理中的消息(
cur_msg)。 - 立即重新触发
__spi_pump_messages任务,继续从队列取下一个消息。 - 这样不断循环,直到队列为空。
- 清空当前处理中的消息(
三、初始化
在使用SPI传输数据前,需要按照以下步骤操作:
初始化消息结构 必须先用
spi_message_init()函数初始化消息结构,这会清空所有字段,并准备好传输列表。添加传输项 每次要添加数据传输时,都需调用
spi_message_add_tail()函数,把新的传输项追加到消息队列末尾。发送消息的两种方式
- 同步模式(直接执行) 调用
spi_sync()函数立即发送消息,这个函数会一直等待直到传输完成。 ❗注意:不能在中断处理函数中使用,且无需设置回调函数。 - 异步模式(后台执行) 使用
spi_async()函数启动传输后立即返回,允许程序继续执行其他任务。 ✅推荐做法:建议设置回调函数,在传输完成后自动触发处理逻辑。 ⚡特性:支持在需要快速响应的场景(如中断上下文)中使用。
- 同步模式(直接执行) 调用
这样操作流程就像排队点餐:先整理好订单(初始化),逐个添加菜品(添加传输项),最后选择"等位取餐"(同步)或"叫号通知"(异步)的方式来完成交易。
以下是单个传输SPI消息事务示例:
char tx_buf[] = {
0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0x40, 0x00, 0x00, 0x00,
0x00, 0x95, 0xEF, 0xBA, 0xAD,
0xF0, 0x0D,
};
char rx_buf[10] = {0,};
int ret;
struct spi_message single_msg;
struct spi_transfer single_xfer;
single_xfer.tx_buf = tx_buf;
single_xfer.rx_buf = rx_buf;
single_xfer.len = sizeof(tx_buff);
single_xfer.bits_per_word = 8;
spi_message_init(&msg);
spi_message_add_tail(&xfer, &msg);
ret = spi_sync(spi, &msg);现在来编写多传输消息事务:
struct {
char buffer[10];
char cmd[2]
int foo;
} data;
struct data my_data[3];
initialize_date(my_data, ARRAY_SIZE(my_data));
struct spi_transfer multi_xfer[3];
struct spi_message single_msg;
int ret;
multi_xfer[0].rx_buf = data[0].buffer;
multi_xfer[0].len = 5;
multi_xfer[0].cs_change = 1;
/* 命令A */
multi_xfer[1].tx_buf = data[1].cmd;
multi_xfer[1].len = 2;
multi_xfer[1].cs_change = 1;
/* 命令B */
multi_xfer[2].rx_buf = data[2].buffer;
multi_xfer[2].len = 10;
spi_message_init(single_msg);
spi_message_add_tail(&multi_xfer[0], &single_msg);
spi_message_add_tail(&multi_xfer[1], &single_msg);
spi_message_add_tail(&multi_xfer[2], &single_msg);
ret = spi_sync(spi, &single_msg);