
📢perf 可以在 CPU Usage 增高的节点上找到具体的引起 CPU 增高的函数,然后我们就可以有针对性地聚焦到那个函数做分析。
一、perf list命令
perf 是 Linux 系统的重要性能分析工具,由知名开发者 Ingo Molnar 开发。它的源代码存放在 Linux 内核源码的 tools 文件夹里。
使用前,你可以先运行 perf list 命令。这个命令会列出大量可监控的事件类型,例如常见的 CPU 事件等。
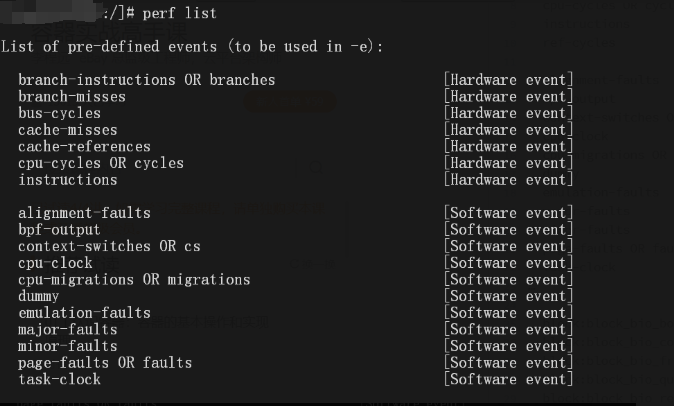
通过perf list命令,我们可以看到每个事件名称后面都标注了类型,比如_Hardware_或_Software_。例如,L1缓存命中属于硬件事件,进程切换属于软件事件。所有事件类型都可以在内核代码的perf_type_id列表中找到。
以下是三种主要的事件类型:
硬件事件:由CPU的性能监控硬件(PMU)直接记录,比如缓存访问、指令执行等。
软件事件:由操作系统内核主动记录,比如进程切换、系统调用等。
跟踪点事件:当程序运行到内核预先设定的观察点时触发的事件,比如文件操作或网络活动。
简单来说,硬件事件来自CPU硬件层,软件事件由操作系统记录,跟踪点事件则像在代码中设置的监控标记。
二、perf record/report命令
perf record 命令 这个命令用来收集程序运行数据,并保存到文件里。常用参数如下:
-e:选择要监控的事件类型(比如硬件事件或软件事件)-a:采集全系统所有进程的数据-p <PID>:只采集某个进程的数据(需要指定进程ID)-o <文件名>:把数据保存到指定文件(默认是 perf.data)-g:显示函数调用关系图(追踪函数调用链)-C <CPU号>:只采集某个CPU核心的数据
示例命令:
perf record -a -g -- sleep 60这条命令会采集系统-wide的60秒数据,并生成函数调用关系图,结果保存在 perf.data 文件里。
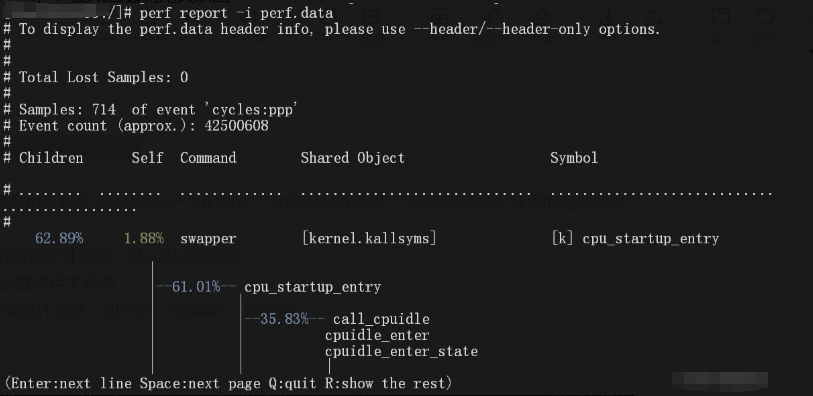
perf report 命令 这个命令用来分析 perf record 生成的数据文件。常用参数:
-i <文件名>:指定要分析的数据文件(不写的话默认用 perf.data)-g:生成函数调用关系图,查看函数间的调用关系--sort <分类项>:按指定条件排序结果,比如按进程ID(PID)、进程名(COMM)、CPU核心等分类统计
简单说明:
先用
perf record收集数据(比如运行某个程序或监控系统一段时间)再用
perf report查看分析结果,可以按函数调用链、进程、CPU等角度查看性能数据
例子如下:
三、perf stat命令
性能优化时,最好先从整体入手。先看看程序运行时的整体数据,再根据重点方向深入分析,别一开始就钻牛角尖,否则可能看不到整体问题。
程序运行慢的原因分两种:
CPU密集型(CPU-Bound):大部分时间在用CPU计算,这种需要优化算法或减少计算量
IO密集型(I/O-Bound):卡在输入输出操作(如读写文件/网络),这时CPU利用率低,需要优化等待时间或并行处理
perf stat是个能快速展示程序整体性能概览的工具。常用参数:
-a:显示所有CPU的数据
-c:指定某个CPU的编号
-e:筛选想查看的具体指标(比如CPU cycles或缓存命中率)
-p:指定要分析的进程ID
先用这个工具确定程序属于哪种类型,再针对性优化会更高效。
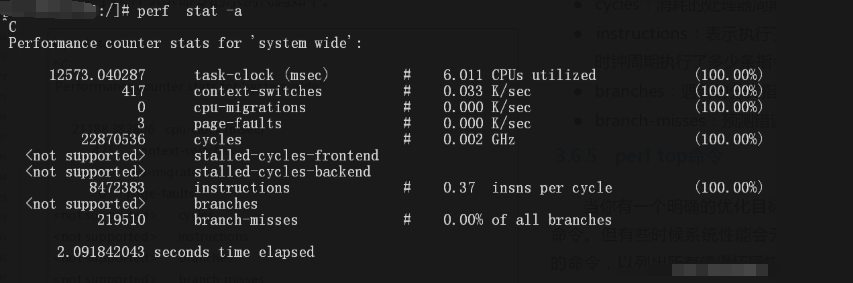
以下是参数的简明解释:
任务时钟(task-clock): 程序实际占用处理器的时间,单位为毫秒。
上下文切换次数(context-switches): 程序运行时,处理器在不同任务间切换的次数。
CPU迁移次数(CPU-migrations): 程序在运行过程中,被移动到不同处理器核心的次数。
缺页错误次数(page-faults): 内存中找不到所需数据块时发生的错误次数。
CPU周期数(cycles): 处理器为完成任务消耗的时钟周期总数。
指令数(instructions): 程序执行的总指令数量。 IPC(每周期指令数):平均每个CPU周期能执行多少条指令。
分支指令数(branches): 程序中遇到的条件跳转(分支)指令的数量。
分支预测错误(branch-misses): 处理器错误预测分支路径的次数(例如,判断条件跳转方向错误)。
核心逻辑简化:
任务时钟 → 程序实际用了多少处理器时间。
上下文切换 → 多任务切换的频率。
CPU迁移 → 程序被挪到其他核心的次数。
缺页错误 → 内存不足时的错误次数。
CPU周期 → 处理器工作的“心跳”次数。
指令与IPC → 程序写了多少代码,以及代码的效率如何。
分支相关 → 程序中的“判断”指令数量及预测失误情况。